Ember projects and addons generated with ember-cli come with a .travis.yml configuration out of the box, so it’s clear why TravisCI has become the default for most Ember projects.
I, however, became quite fond of CircleCI while using it at my last employer.
It has a great dashboard UI and a generous free tier, especially for open source projects.
After CircleCI 2.0 became generally available last summer, I transitioned our Ember app at $EMPLOYER over to it and found that the new version really had some interesting benefits for our project. While I’m not at liberty to share the details of the $EMPLOYER project, I thought it would be interesting to revisit some of the things I learned then and make some general recommendations for using CircleCI with Ember applications and addons.
Using CircleCI 2.0 with Ember Applications
I have a simple Ember application that I use for experimentation that is open sourced at rebase-interactive/gitzoom-web. I’m going to use that project to iterate on a CircleCI 2.0 configuration.
First, I adapt the default .travis.yml that gets generated by ember-cli into an equivalent single-process configuration for CircleCI 2.0:
- While CircleCI 1.0 used a
circle.ymlfile at the project root, CircleCI 2.0 expects the configuration file to be namedconfig.ymland be located inside a.circlecidirectory in the project root. - By default, CircleCI 2.0 will run a job named
build. - CircleCI 2.0 runs all its processes inside of Docker containers. I’m using a prebuilt image for Node 6, and I’ve chosen the
-browsersvariant so that Chrome comes pre-installed in the container. - While the the default
.travis.ymlsets theJOBSenvironment variable to1, I am setting it to2since I know that my CircleCI container can run two concurrent processes. - I explicitly tell CircleCI to use
~/gitzoom-webas theworking_directoryfor this job. This makes it easy to refer to the location of my project in later steps. - I define a series of
stepsfor CircleCI 2.0 to run in sequence:checkoutis a special step that checks out the source code (to theworking_directoryby default)- Most steps use
runand have both aname(displayed in the CircleCI UI) and acommand(run via shell). - Since I’m using Yarn on this project, I use
yarninstead ofnpmto install my dependencies and run my lint and test scripts. - In order to run
embercommands (like theember testcommand found in myyarn testscript), I need to add~/gitzoom-web/node_modules/.binto the container’sPATH. I do this with a one-line unnamedrunstep. deployis another special step. It works just like arunstep except that in jobs using parallelism, it will only run in one node and only if all nodes succeed (though that doesn’t apply here). I use|to define a multi-line command that will only execute on themasterbranch.
While this gets my project building on CircleCI 2.0, it’s not really taking advantage of any of the features that make CircleCI 2.0 so interesting. I’ll improve things by caching my installed dependencies next.
Caching Dependencies
Caching in CircleCI 2.0 lets you reuse the data from expensive fetch operations from previous runs of a job to speed up future runs of that job.
To cache the contents of my node_modules directory between test runs, I add two new steps surrounding the installation of my NPM dependencies: save_cache and restore_cache.
- First, I define a
save_cachestep after my dependencies are installed.- CircleCI 2.0 caches are immutable, so once a cache has been written with a specific
key, it cannot be overwritten. I use akeythat increases in specificity left to right:- The
v1-version prefix is a convenience that allows me to invalidate all preexisting immutable caches by bumping up to a new version prefix (such asv2-). deps-defines this as my dependency cache, as opposed to some other cache I may add in the future such as a source cache.{{ .Branch }}-uses a template to dynamically insert the name of the Git branch that is currently being built.{{ checksum "yarn.lock" }}generates a hash of my Yarn lockfile, ensuring that I get a new unique cache key any time the contents of my lockfile change.
- The
- I can include any number of paths in my cache, but in this case I only want to cache
./node_modules(a path relative to myworking_directory).
- CircleCI 2.0 caches are immutable, so once a cache has been written with a specific
- Prior to installing my dependencies, I can now use
restore_cacheto look for an existing cache to pre-populate mynode_modules. By defining multiplekeysof decreasing specificity, I increase my chances of a cache hit as cache retrieval is prefix-matched:- First I look for a full match for the key defined in my
save_cachestep. If I’m on the same branch and my lockfile has not changed, I will retrieve a full restore of mynode_modules. - Next I look for a match up to and including the current Git branch. Even if my lockfile has changed since the last build, I will still retrieve the pre-change
node_modules. - Finally, I look for any existing dependency cache. Since it will return the latest prefix-matching cache, this still should be better than a full recreation of my
node_modules.
- First I look for a full match for the key defined in my
It’s possible to also cache the full source code of a project, which may be beneficial for larger projects. When project source has been recovered from cache, the checkout step will perform git pull instead of git clone.
For smaller projects like this one though, git clone is often faster than restore_cache.
Now the real fun begins: Workflows!
Defining a CircleCI 2.0 Workflow
CircleCI 2.0’s workflow feature lets me break up the build into smaller parts, each of which runs in its own isolated container. If one job in my workflow fails, I can rerun just the failed job instead of having to run the entire build over in its entirety. I can also define which jobs depend on which other jobs, which lets me parallelize parts of my build that are able to run independently from each other.
There’s a lot going on here, but I’ll try to break it down a bit at a time.
- Instead of one
buildjob, there are now five distinct jobs:checkout_code,install_dependencies,lint_js,run_tests, anddeploy_production.- Since each job uses the same Docker image and working directory, I’ve defined these options at the top of the file using Yaml anchor syntax so that I don’t have to repeat them. Instead I include them in each job with
<<: *defaults. - The
checkout_codejob runs the specialcheckoutstep and then passes the checked out code to future jobs usingpersist_to_workspace. By defining therootas.(relative toworking_directory) and thepathsas.(relative toroot), the entire contents of the working directory are passed along for future jobs to use.Workspaces pass data along to other jobs in a workflow; caches pass data along to the same job in future workflow runs.
- The
install_dependenciesjob starts out by usingattach_workspaceto download the results ofcheckout_codeinto the working directory (at: .) of its container. It restores the dependency cache, installs dependencies, and caches the dependencies for future runs of the job. Finally, it usespersist_to_workspaceto pass the installed dependencies forward to future steps in the workflow. - The
lint_jsjob attaches the workspace and then runs the JavaScript linter command. It does not persist anything to the workspace as it does not produce anything used by upcoming jobs. - The
run_testsjob attaches the workspace and then runs the test script. It likewise does not persist anything to the workspace. - The
deploy_productionjob runs the deployment command. Notice that the command no longer includes a branch conditional, as I define that filtering condition in the workflow itself.
- Since each job uses the same Docker image and working directory, I’ve defined these options at the top of the file using Yaml anchor syntax so that I don’t have to repeat them. Instead I include them in each job with
- After defining the individual jobs, I chain them together by defining a workflow called
test_and_deploy(this can be named anything that makes sense for the project). Here I list thejobsthat will be performed as part of the workflow.checkout_coderuns immediately.install_dependenciesrequirescheckout_code, so it waits for that job to succeed before running.lint_jsandrun_testsboth requireinstall_dependencies, so they wait for that job to succeed and then they both start running (in parallel containers)!deploy_productionrequires bothlint_jsandrun_tests, so it waits for both jobs to succeed before running. It additionally includes a branch filter so that it only runs on themasterbranch.
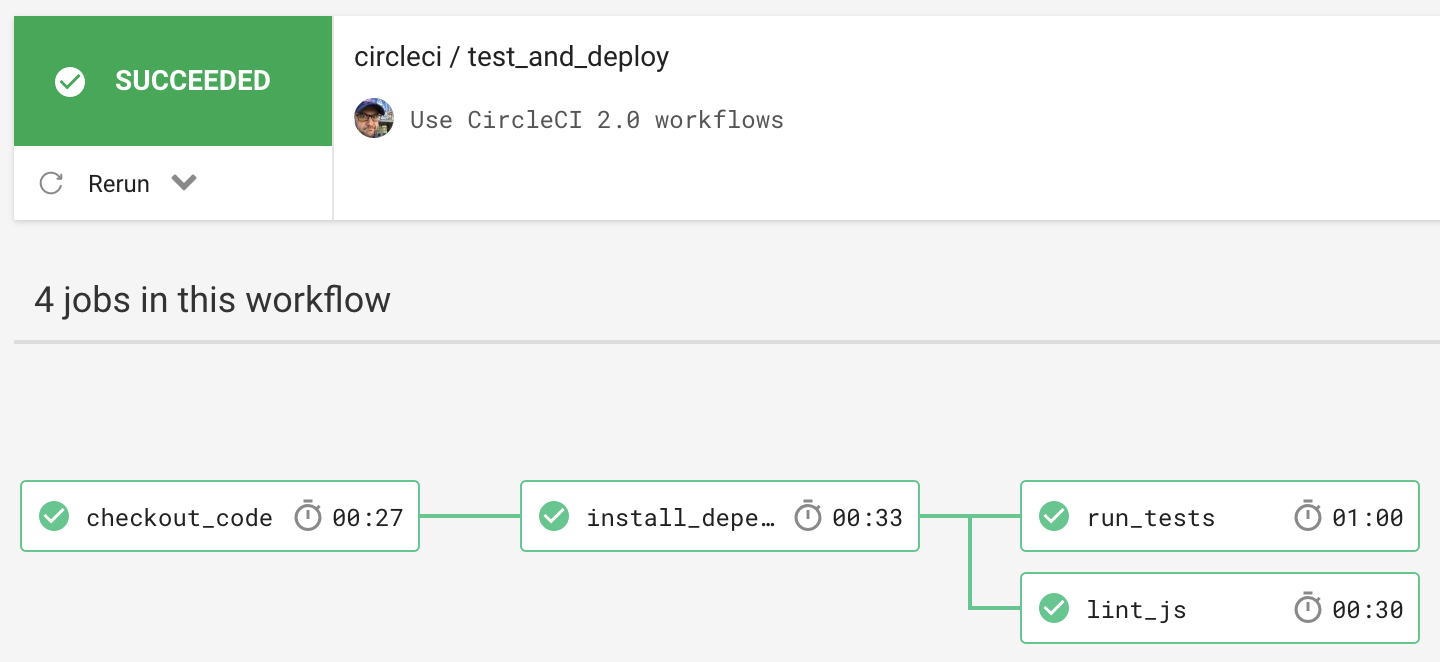
The result is that each job runs independently of the others and in the order defined by the workflow (with deploy_production not shown as this build was not run on master):
Filtering Jobs by Tag
While branch-based job filtering is fairly straightforward (jobs run on all branches by default and filtering is only necessary to limit branches), tag-based filtering is a bit more complicated.
By default, workflow jobs do not run on tags at all. This means that if I want my deploy job to run only when I’ve tagged a release, then I must modify the workflows portion of my configuration:
- I whitelist every pre-deploy job to run on all tags using regex
/.*/. This runs the tests on tags, and allows me to verify that my tests all pass before deploying. - I define two filters to control when the
deploy_productionjob is run:- It runs only on tags that match my release tag format:
/v[0-9]+\.[0-9]+\.[0-9]+/ - It ignores all (
/.*/) branches.
- It runs only on tags that match my release tag format:
Now my deployment script will only run on tagged releases, and only after the previous jobs (including tests and linting) pass.
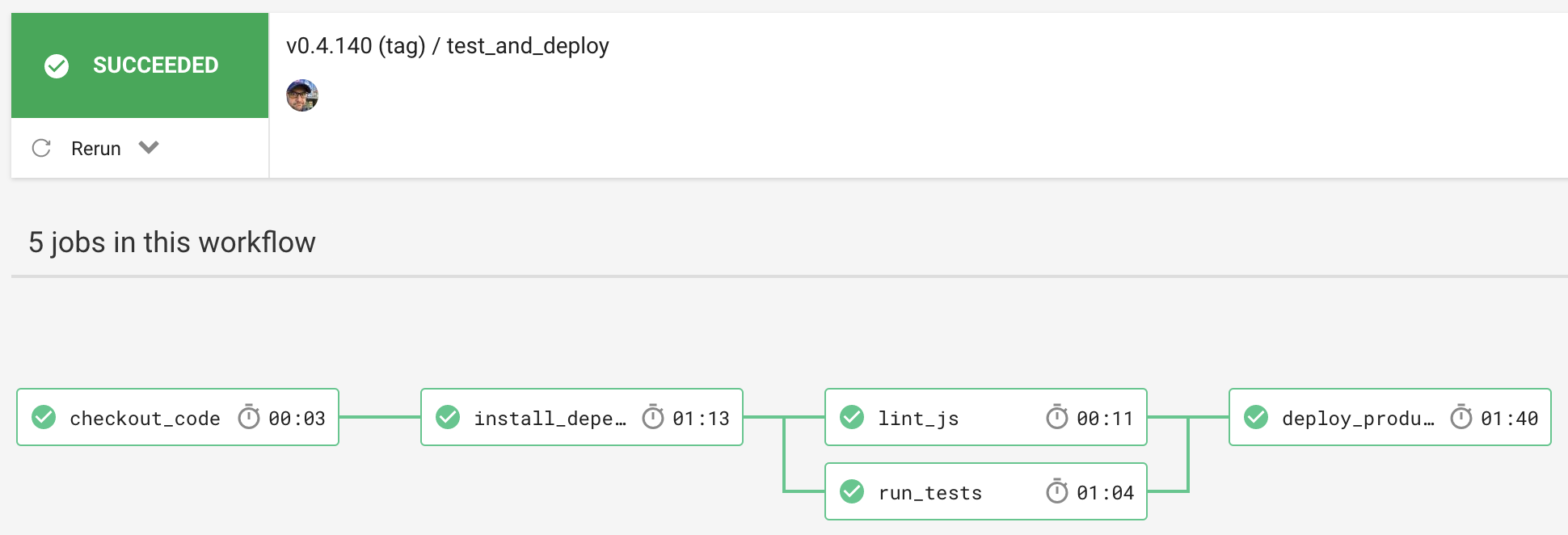
Since the deploy_production job requires both run_tests and lint_js to succeed, the workflow looks like this on tagged releases:
Additional Uses of CircleCI 2.0 Workflows
Once I begin breaking my CI builds down into smaller pieces, a number of other potential use cases become apparent:
- At $EMPLOYER, I used CircleCI workflows to deploy to multiple deploy targets simultaneously. We had two copies of our Ember application running in Staging: one against the Staging API server, and one against the Production API server. By running the deploy scripts for these environments concurrently, our CircleCI Staging build didn’t take any longer to deploy than other branches with only one deploy target.
- Using the
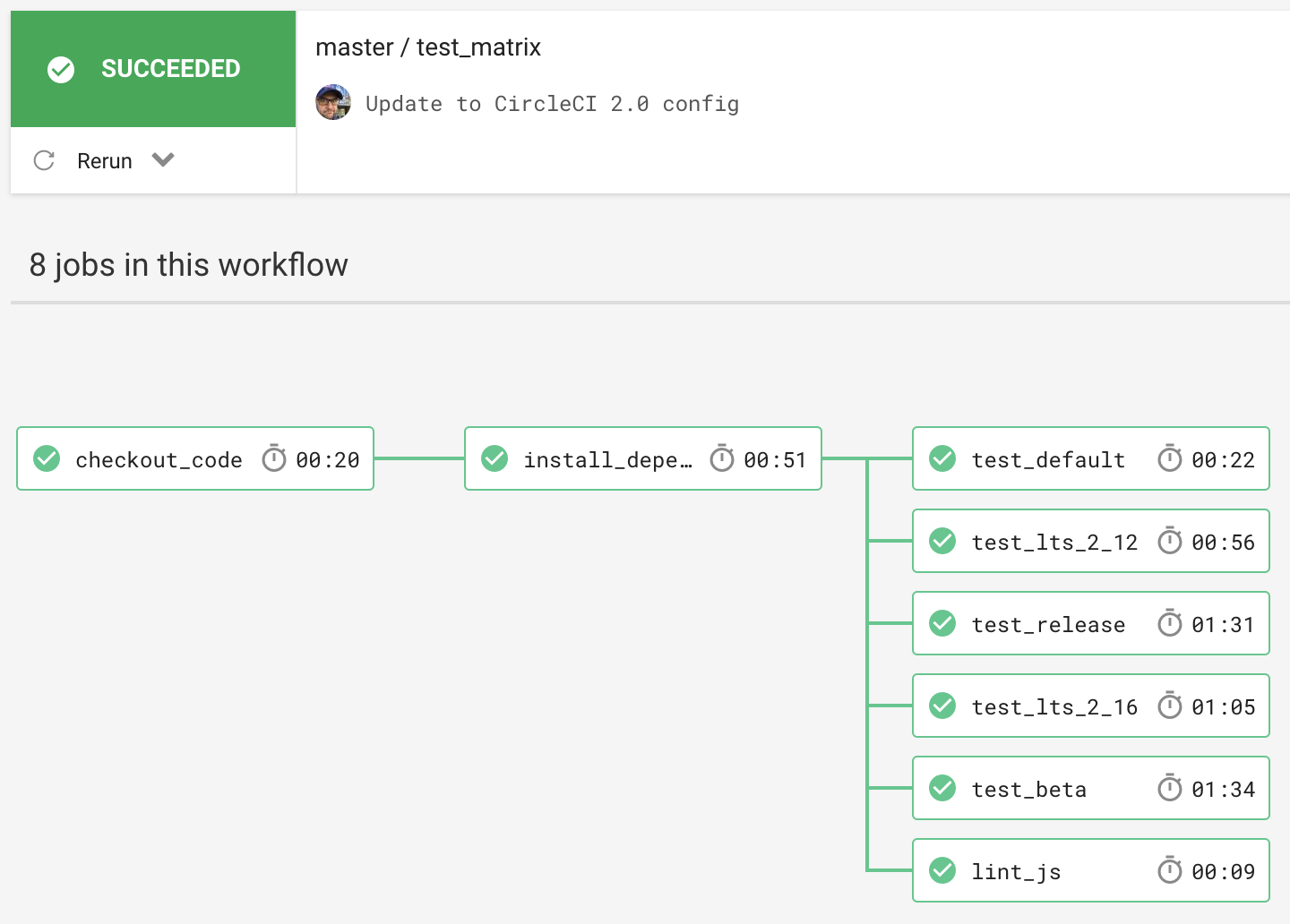
--filterargument forember test, it would be possible to segment out different types of tests as separate workflow jobs and run acceptance tests separately from integration tests and unit tests. - For addons using ember-try to test against multiple versions of Ember, it’s possible to break out each ember-try scenario into a separate job and run them in parallel. For my ember-octicons addon, see the CircleCI configuration here that results in the following workflow:
If you try out CircleCI workflows with your Ember application or addon, I’d love to hear what other ideas you come up with!
Like this post on CircleCI workflows and ready to get this sort of workflow working with your own codebase? 201 Created has worked on dozens of apps with Fortune 50 companies and Y-combinator startups. Visit 201-created.com or email hello@201-created.com to talk with us.